In this present day and age we are blessed to have new technology that help us in our daily lives. Such technology is the Video technology. Videos have been around for quite some time and its uses have evolved over the years. As a matter of fact, for the children of today, a video is something common. We sometimes forget that people in the past didn't have the same technology that we have. Back then, the "videos" that people knew were different from the "videos" that we now know. For example, in Figure 1 we see a Zoetrope, a device that consists of a hollow drum with pictures positioned at the bottom third of the drum. These pictures make-up a sequence of events. These pictures can be viewed via slits on the drum. The drum is mounted on a spindle such that one may be able to spin the drum. Upon spinning, one can see the pictures as if they were "moving". [1]
 |
Figure 1. A Zoetrope [1]
|
The videos of today may seem far from what "videos" were before, however the essential concept is preserved. Videos are made up of images constituting a sequence of events. They're applications or uses may be different but the main concept remains relatively unchanged.
Also, images of successive events are very useful in gathering details regarding those specific events since it gives us an idea of the time element involved. This is contrary to a single image which only gives us information at a single point in time. Using image processing techniques we can extract information in a particular situation even without actually being there. Therefore, as an example, I will be discussing the Physics behind a free falling ball captured on video - an experiment me and my partner Rusty Lopez did for this post.
First off, the materials we used are the following
- Sony Cyber-Shot W310 Camera (Thanks to Eloise Anguluan)
- An orange ball (Thanks to Eloise Anguluan again)
- A metal ruler (Thank you IPL)
- Scilab (our image processing tool)
- Stoik Video Converter
- VirtualDub
We recorded our video using a Sony Cyber-Shot W310 camera. We then used Stoik Video converter to change some of the details in our video such as frame size and frame rate. We also compressed the video into black and white and "muted" out the sound. The output format of our converted video is in AVI for PC small. After doing this, we marked or cropped out the important segment of the video using VirtualDub. Make sure to save the "cropped" version as an AVI file. We then loaded the cropped version of the video into VirtualDub with the intention of "segmenting" it into frames. This can be done by clicking "File" then choosing "Export" and finally selecting "Save as Image Sequence". The resulting frames are shown below.
 |
Figure 2. Frames from the video captured. The time
interval between the images shown is 0.03 seconds.
|
Now for the main image processing part. Using Scilab, we segmented the image using a patch of the ball from the image. Specifically we used Parametric segmentation to segment the image. Upon segmentation, we then binarized the image and computed for the centroid of the segmented portion. The centroid or geometric center [2] will give us the idea of the path taken by the ball as it was falling. We then combined each centroid extracted from the different frames to form one single image given by Figure 3.
 |
Figure 3. Path taken by the freely falling ball
represented by the centroid of each frame. |
From here, we identified the pixel position of each centroid. Noting that we can convert pixel position to actual distance using an image processing technique we learned from our very first activity, we then calculated for the actual distances for each pixel position given in Figure 2. Plotting this with respect to the time we get.
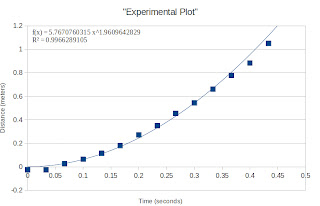 |
Figure 4. Distance versus Time plot of a free falling ball. The
distance was calculated through image processing means. |
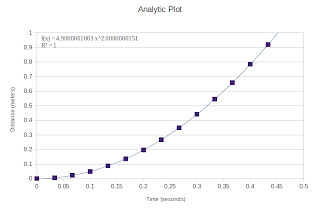 |
Figure 5. Distance versus Time plot of a free falling ball.
The distance was computed using the equation for the
falling distance of a free falling object.
|
Note that the equation for falling distance is given by
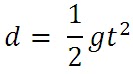 |
Equation 1. Falling distance equation,
where d is the falling distance, g is the
acceleration due to gravity and t is the
|
Therefore, upon fitting our plot with a power function we obtain g. The values obtained are given in Table 1.
 |
Table 1. Obtained Acceleration due to gravity (a) analytic
computation, and (b)using image processing techniques. |
Note that the 1.8 m/s^2 difference can be explained by the "tilt" in the camera angle while capturing. This tilt causes a variation in our distance computations. Nevertheless, i'm so happy to have posted a blog (almost) on time again! :) Thank you Lord! :D And for that, I give myself a grade of 9/10. The one point deduction is partly due to the relatively large error of 18 %. :)
God bless everyone! Have a great weekend ahead! :)
References:
[1] The zoetrope, retrieved September 29, 2011,
http://www.exeter.ac.uk/bdc/young_bdc/animation/animation4.htm
[2] Centroid, retrieved September 30, 2011, http://en.wikipedia.org/wiki/Centroid
[3] Soriano, M., A17 - Basic Video Processing, Applied Physics 186 Activity Manual, 2008











































{kind=link}